Akka 系列(八):Akka persistence 设计理念之 CQRS
这一篇文章主要是讲解Akka persistence的核心设计理念,也是CQRS(Command Query Responsibility Segregation)架构设计的典型应用,就让我们来看看为什么Akka persistence会采用CQRS架构设计。
CQRS
很多时候我们在处理高并发的业务需求的时候,往往能把应用层的代码优化的很好,比如缓存,限流,均衡负载等,但是很难避免的一个问题就是数据的持久化,以致数据库的性能很可能就是系统性能的瓶颈,我前面的那篇文章也讲到,如果我们用数据库去保证记录的CRUD,在并发高的情况下,让数据库执行这么多的事务操作,会让很多数据库操作超时,连接池不够用的情况,导致大量请求失败,系统的错误率上升和负载性能下降。
既然这样,那我们可不可借鉴一下读写分离的思想呢?假使写操作和同操作分离,甚至是对不同数据表,数据库操作,那么我们就可以大大降低数据库的瓶颈,使整个系统的性能大大提升。那么CQRS到底是做了什么呢?
我们先来看看普通的方式:
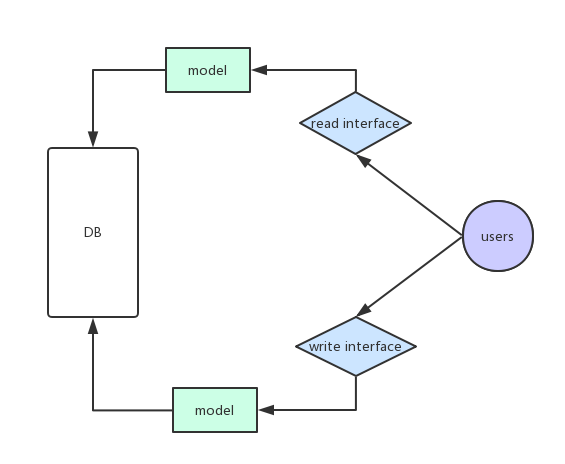
我们可以看出,我们对数据的请求都是通过相应的接口直接对数据库进行操作,这在并发大的时候肯定会对数据库造成很大的压力,虽然架构简单,但在面对并发高的情况下力不从心。
那么CQRS的方式有什么不同呢?我们也来看看它的执行方式:
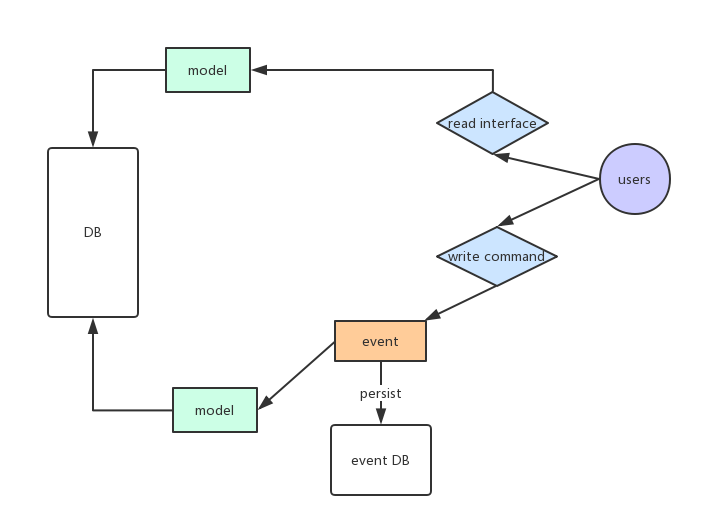
乍得一看,似乎跟普通的方式没什么不同啊,不就多了一个事件和存储DB么,其实不然,小小的改动便是核心理念的转换,首先我们可以看到在CQRS架构中会多出一个Event,那它到底代表着什么含义呢?其实看过上篇文章的同学很容易理解,Event是我们系统根据请求处理得出的一个领域模型,比如一个修改余额操作事件,当然这个Event中只会保存关键性的数据。
很多同学又有疑问了,这不跟普通的读写分离很像么,难道还隐藏着什么秘密?那我们就来比较一下几种方式的不同之处:
1.单数据库模式
- 写操作会产生互斥锁,导致性能降低;
- 即使使用乐观锁,但是在大量写操作的情况下也会大量失败;
2.读写分离
- 读写分离通过物理服务器增加,负荷增加;
- 读写分离更适用于读操作大于写操作的场景;
- 读写分离在面对大量写操作的情况下还是很吃力;
3.CQRS
- 普通数据的持久化和Event持久化可以使用同一台数据库;
- 利用架构设计可以使读和写操作尽可能的分离;
- 能支撑大量写的操作情况;
- 可以支持数据异步持久,确保数据最终一致性;
从三种方式各自的特点可以看出,单数据库模式的在大量读写的情况下有很大的性能瓶颈,但简单的读写分离在面对大量写操作的时候也还是力不从心,比如最常见的库存修改查询场景:
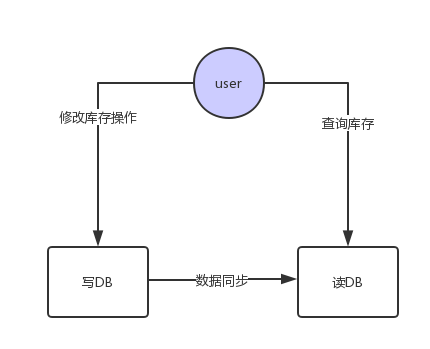
我们可以发现在这种模式下写数据库的压力还会很大,而且还有数据同步,数据延迟等问题。
那么我们用CQRS架构设计会是怎么样呢:
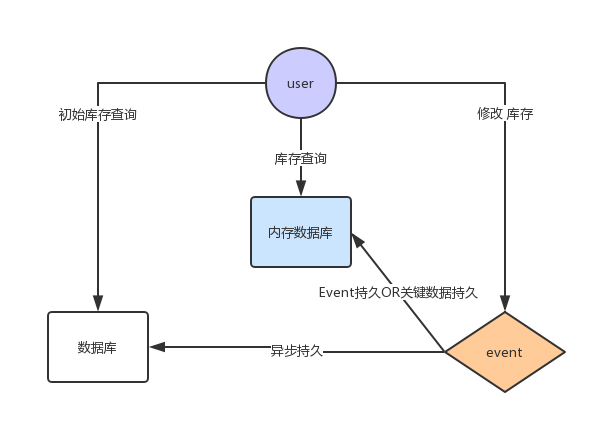
首先我们可以业务模型进行分离,对不同的查询进行分离,另外避免不了的同一区间数据段进行异步持久化,在保证数据一致性的情况下提升系统的吞吐量。这种设计我们很少会遇到事务竞争,另外还可以使用内存数据库(当然如果是内存操作那就最快)来提升数据的写入。(以上的数据库都可为分布式数据库,不担心单机宕机)
那么CRQS机制是怎么保证数据的一致性的呢?
从上图中我们可以看出,一个写操作我们会在系统进行初步处理后生成一个领域事件,比如a用户购买了xx商品1件,b用户购买了xx商品2件等,按照普通的方式我们肯定是直接将订单操作,库存修改操作一并放在一个事务内去操作数据库,性能可想而知,而用CQRS的方式后,首先系统在持久化相应的领域事件后和修改内存中的库存(这个处理非常迅速)后便可马上向用户做出反应,真正的具体信息持久可以异步进行,当然若是当在具体信息持久化的过程中出错了怎么办,系统能恢复正确的数据么,当然可以,因为我们的领域事件事件已经持久化成功了,在系统恢复的时候,我们可以根据领域事件来恢复真正的数据,当然为了防止恢复数据是造成数据丢失,数据重复等问题我们需要制定相应的原则,比如给领域事件分配相应id等。
使用CQRS会带来性能上的提升,当然它也有它的弊端:
- 使系统变得更复杂,做一些额外的设计;
- CQRS保证的是最终一致性,有可能只适用于特定的业务场景;
Akka Persistence 中CQRS的应用
通过上面的讲解,相信大家对CQRS已经有了一定的了解,下面我们就来看看它在Akka Persistence中的具体应用,这里我就结合上一篇文章抽奖的例子,比如其中的LotteryCmd便是一个写操作命令,系统经过相应的处理后得到相应的领域事件,比如其中LuckyEvent,然后我们将LuckyEvent进行持久化,并修改内存中抽奖的余额,返回相应的结果,这里我们就可以同时将结果反馈给用户,并对结果进行异步持久化,流程如下:
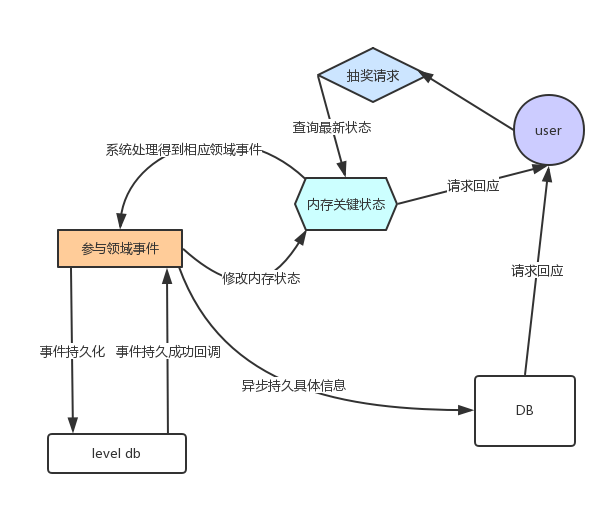
可以看出,Akka Persistence的原理完全是基于CQRS的架构设计的,另外Persistence Actor还会保存一个内存状态,相当于一个in memory数据库,可以用来提供关键数据的存储和查询,比如前面说到的库存,余额等数据,这部分的设计取决于具体的业务场景。
阅读Akka Persistence相关源码,其的核心就在于PersistentActor接口中的几个持久方法,比如其中的
1 | def persist[A](event: A)(handler: A ⇒ Unit): Unit |
等方法,它们都有两个参数,一个是持久化的事件,一个是持久化后的后续处理逻辑,我们可以在后续handler中修改Actor内部状态,向外部发送消息等操作,这里的模式就是基于CQRS架构的,修改状态有事件驱动,另外Akka还可以在系统出错时,利用相应的事件恢复Actor的状态。
总结
总的来说,CQRS架构是一种不同于以往的CRUD的架构,所以你在享受它带来的高性能的同时可能会遇到一些奇怪的问题,当然这些都是可以解决的,重要的是思维上的改变,比如事件驱动,领域模型等概念,不过相信当你理解并掌握它之后,你便会爱上它的。