Kafka 学习笔记(二) :初探 Kafka
看完上一篇,相信大家对消息系统以及Kafka的整体构成都有了初步了解,学习一个东西最好的办法,就是去使用它,今天就让我们一起窥探一下Kafka,并完成自己的处女作。
消息在Kafka中的历程
虽然我们掌握东西要一步一步来,但是我们在大致了解了一个东西后,会有利于我们对它的理解和学习,所以我们可以先来看一下一条消息从发出到最后被消息者接收到底经历了什么?
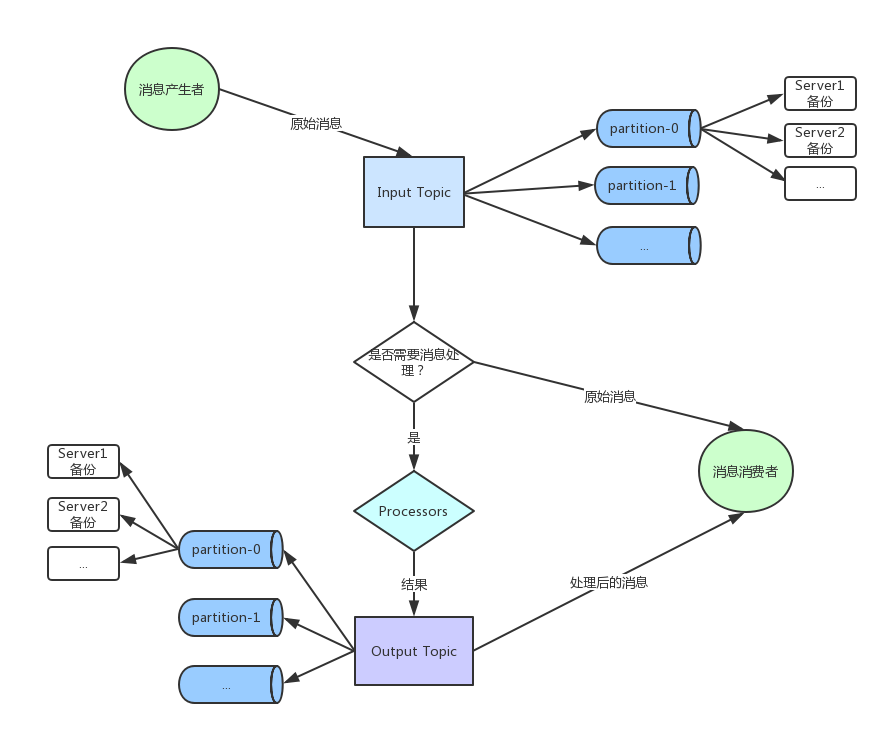
上图简要的说明了消息在Kafka中的整个流转过程(假设已经部署好了整个Kafka系统,并创建了相应的Topic,分区等细节后续再单独讲):
- 1.消息生产者将消息发布到具体的Topic,根据一定算法或者随机被分发到具体的分区中;
- 2.根据实际需求,是否需要实现处理消息逻辑;
- 3.若需要,则实现具体逻辑后将结果发布到输出Topic;
- 4.消费者根据需求订阅相关Topic,并消费消息;
总的来说,怎么流程还是比较清晰和简单的,下面就跟我一起来练习Kafka的基本操作,最后实现一个单词计数的小demo。
基础操作
以下代码及相应测试在以下环境测试通过:Mac OS + JDK1.8,Linux系统应该也能跑通,Windows有兴趣的同学可以去官网下载相应版本进行相应的测试练习。
下载Kafka
Mac系统同学可以使用brew安装:
1 | brew install kafka |
Linux系统同学可以从官网下载源码解压,也可以直接执行以下命令:
1 | cd |
启动
Kafka使用Zookeeper来维护集群信息,所以这里我们先要启动Zookeeper,Kafka与Zookeeper的相关联系跟结合后续再深入了解,毕竟不能一口吃成一个胖子。
1 | bin/zookeeper-server-start.sh config/zookeeper.properties |
接着我们启动一个Kafka Server节点:
1 | bin/kafka-server-start.sh config/server.properties |
这时候Kafka系统已经算是启动起来了。
创建Topic
在一切就绪之后,我们要开始做极其重要的一步,那就是创建Topic,Topic是整个系统流转的核心,另外Topic本身也包含着很多复杂的参数,比如复制因子个数,分区个数等,这里为了从简,我们将对应的参数都设为1,方便大家测试:
1 | bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kakfa-test |
其中参数的具体含义:
| 属性 | 功能 |
|---|---|
| –create | 代表创建Topic |
| –zookeeper | zookeeper集群信息 |
| –replication-factor | 复制因子 |
| –partitions | 分区信息 |
| –topic | Topic名称 |
这时候我们已经创建好了一个叫kakfa-test的Topic了。
向Topic发送消息
在有了Topic后我们就可以向其发送消息:
1 | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kakfa-test |
然后我们向控制台输入一些消息:
1 | this is my first test kafka |
这时候消息已经被发布在kakfa-test这个主题上了。
从Topic获取消息
现在Topic上已经有消息了,现在可以从中获取消息被消费:
1 | bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kafka-test --from-beginning |
这时候我们可以在控制台看到:
1 | this is my first test kafka |
至此我们就测试了最简单的Kafka Demo,希望大家能自己动手去试试,虽然很简单,但是这能让你对整个Kafka流程能更熟悉。
WordCount
下面我们来利用上面的一些基本操作来实现一个简单WordCount程序,它具备以下功能:
- 1.支持词组持续输入,即生产者不断生成消息;
- 2.程序自动从输入Topic中获取原始数据,然后经过处理,将处理结果发布在计数Topic中;
- 3.消费者可以从计数Topic获取相应的WordCount的结果;
1.启动kafka
与上文的启动一样,按照其操作即可。
2.创建输入Topic
1 | bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic kafka-word-count-input --partitions 1 --replication-factor 1 |
3.向Topic输入消息
1 | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kafka-word-count-input |
4.流处理逻辑
这部分内容是整个例子的核心,这部分代码有Java 8+和Scala版本,个人认为流处理用函数式语法表达的更加简洁清晰,推荐大家用函数式的思维去尝试写以下,发现自己再也不想写Java匿名内部类这种语法了。
我们先来看一个Java 8的版本:
1 | public class WordCount { |
是不是很惊讶,用java也能写出如此简洁的代码,所以说如果有适用场景,推荐大家尝试的用函数式的思维去写写java代码。
我们再来看看Scala版本的:
1 |
|
可以发现使用Java 8函数式风格编写的代码已经跟Scala很相似了。
5.启动处理逻辑
很多同学电脑上并没有装sbt,所以这里演示的利用Maven构建的Java版本,具体执行步骤请参考戳这里kafka-word-count上的说明。
6.启动消费者进程
最后我们启动消费者进程,并在生产者中输入一些单词,比如:
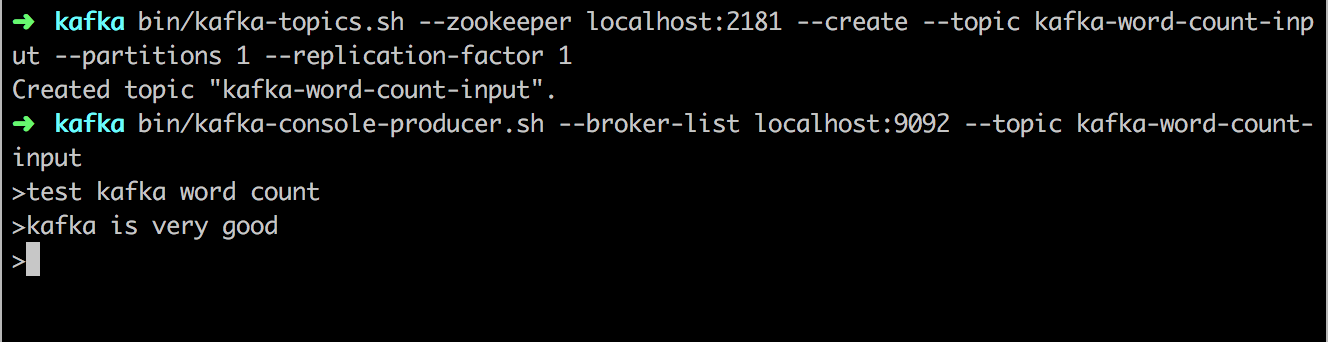
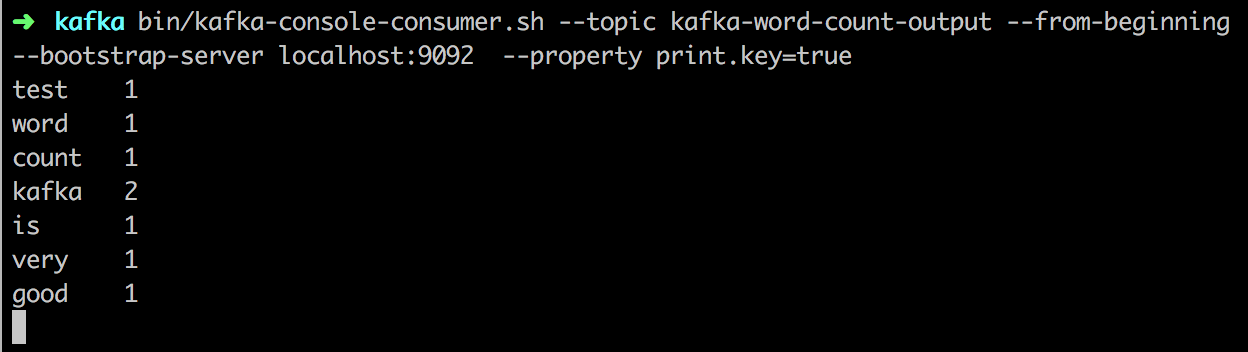
最后我们可以在消费者进程中看到以下输出:
1 | bin/kafka-console-consumer.sh --topic kafka-word-count-output --from-beginning --bootstrap-server localhost:9092 --property print.key=true |
总结
本篇文章主要是讲解了Kafka的基本运行过程和一些基础操作,但这是我们学习一个东西必不可少的一步,只有把基础扎实好,才能更深入的去了解它,理解它为什么这么设计,我在这个过程中也遇到很多麻烦,所以还是希望大家能够自己动手去实践一下,最终能收获更多。